Most Claude Code setups are static. You write a CLAUDE.md, list your conventions, and hope Claude follows them. When it doesn’t, you correct it. Next session, it forgets. You correct it again.
This guide builds something different: a system where every correction you make gets captured and logged, repeated corrections automatically become permanent rules, discovered patterns get verified before they’re trusted, and a periodic audit command decides what stays, what gets promoted, and what gets pruned.
The useful patterns survive. Outdated rules get removed. The system gets fitter every session.
What You’re Building
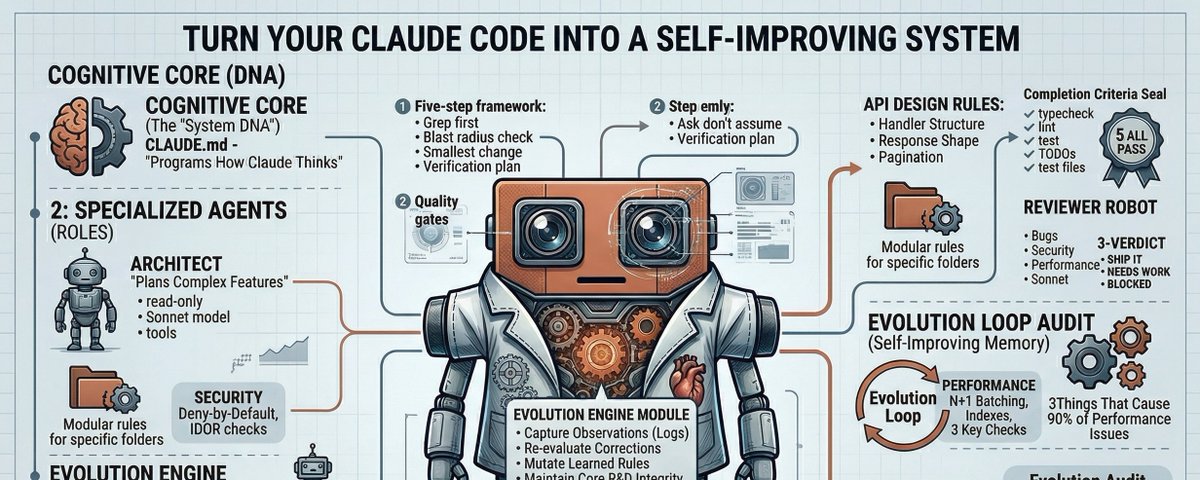
The system has four layers:
Layer 1 — The cognitive core. A CLAUDE.md that programs how Claude thinks, not just what it knows. It includes a decision framework Claude runs before writing any code, and quality gates it checks before calling anything done.
Layer 2 — Specialized agents. Two subagent personas — an architect who plans and a reviewer who validates — spawned for focused work in isolated context windows.
Layer 3 — Path-scoped rules. Instruction files that only load when Claude is working with matching file paths. Security rules activate in your auth code. API design rules activate in your handlers. Performance rules load everywhere. Claude’s context stays lean because irrelevant rules never load.
Layer 4 — The evolution engine. A memory system that captures corrections and codebase observations, auto-verifies them with grep checks, and promotes confirmed patterns into permanent rules. This is the layer that makes the system genuinely self-improving.
Folder Structure
Here’s everything you’re creating:
your-project/
├── CLAUDE.md # Cognitive core (loads into every session)
└── .claude/
├── settings.json # Permissions, safety, and hooks
│
├── rules/ # Path-scoped instruction files
│ ├── core-invariants.md # Critical rules that load on every file
│ ├── security.md # Auth, input validation, data handling
│ ├── api-design.md # Handler patterns, response shapes
│ └── performance.md # N+1, indexes, unbounded queries
│
├── agents/ # Specialized subagents
│ ├── architect.md # Plans complex features (read-only tools)
│ └── reviewer.md # Validates before commits (read-only tools)
│
├── commands/ # Slash commands (/project:name)
│ ├── review.md # Pre-commit review pipeline
│ ├── fix-issue.md # End-to-end bug fix from GitHub issue
│ ├── boot.md # Session primer + verification sweep
│ ├── evolve.md # Self-improvement audit
│ └── sync-commands.md # Auto-detect toolchain and update CLAUDE.md
│
└── memory/ # Learning infrastructure
├── README.md # Memory system protocol
├── learned-rules.md # Graduated patterns with verify: checks
├── evolution-log.md # Audit trail of evolution decisions
├── corrections.jsonl # User corrections (auto-created)
├── observations.jsonl # Verified codebase discoveries (auto-created)
├── violations.jsonl # Rule violations from sweeps (auto-created)
└── sessions.jsonl # Session scorecards and trends (auto-created)
Note on
.claude/commands/: Slash commands in Claude Code live as.mdfiles directly in.claude/commands/. They’re invoked as/project:filename— socommands/review.mdbecomes/project:review. There’s no subdirectory nesting needed.
Step 1: Create the Folder Structure
mkdir -p .claude/rules
mkdir -p .claude/agents
mkdir -p .claude/commands
mkdir -p .claude/memory
Step 2: CLAUDE.md — The Cognitive Core
This is the most important file in the system. It loads directly into Claude’s context for every session and shapes how it thinks. Keep it under 150 lines — beyond that, instruction adherence degrades because the context becomes too noisy. Domain-specific rules belong in .claude/rules/ files, not here.
Create CLAUDE.md in your project root (not inside .claude/):
# Self-Evolving Engineering System
You are a principal engineer that gets smarter every session. You ship working software, think in systems, and continuously improve how you operate.
## Before You Write Any Code
Every time. No exceptions.
1. **Grep first.** Search for existing patterns before creating anything. If a convention exists, follow it. Run `grep -r "similar_term" src/` before writing a single line.
2. **Blast radius.** What depends on what you're changing? Check imports, tests, and consumers. Unknown blast radius = not ready to code.
3. **Ask, don't assume.** Ambiguous request? Ask ONE clarifying question. Don't guess, don't ask five questions. One, then move.
4. **Smallest change.** Solve what was asked. No bonus refactors. No unrequested features. Scope creep is a bug.
5. **Verification plan.** How will you prove this works? Answer this before writing code.
## Commands
<!-- REPLACE THESE with your project's actual commands. They do not auto-detect.
Run /project:sync-commands on first setup to generate the correct values. -->
npm run dev # Start dev server
npm run test # Run tests
npm run lint # Lint check
npm run build # Production build
npm run typecheck # TypeScript type checking
## Architecture
src/
core/ # Pure business logic. No framework imports.
api/ # HTTP layer. Thin handlers calling core/.
services/ # External boundaries (DB, APIs, queues).
types/ # Shared TypeScript types and schemas.
utils/ # Pure stateless utility functions.
Dependency flow: api/ -> core/ -> types/ and api/ -> services/ -> types/.
Core never imports from api/ or services/.
## Conventions
- TypeScript strict mode. No `any`. No `@ts-ignore` without a linked issue.
- Error pattern: `{ data: T | null, error: AppError | null }`. Never throw across module boundaries.
- Validation: zod on every external input before it touches logic.
- Naming: camelCase functions, PascalCase types, SCREAMING_SNAKE constants.
- Imports: @/ absolute paths. Order: node > external > internal > relative > types.
- No console.log. Use a structured logger with levels.
- Functions: max 30 lines, max 3 nesting levels, max 4 parameters.
- Comments: explain WHY, never WHAT. Delete dead code.
## Testing
- Test names as specs: `should return 404 when user does not exist`.
- Arrange-Act-Assert. Mock only at boundaries.
- Edge cases: empty, null, single element, boundary, duplicates, malformed input.
## Security Non-Negotiables
- Deny-by-default on all endpoints. Parameterized queries only.
- No secrets in code. Rate limit auth endpoints. Sanitize all rendered strings.
- Never log PII, tokens, or secrets.
## Completion Criteria
ALL must pass before any task is done:
1. `npm run typecheck` — zero errors
2. `npm run lint` — zero errors
3. `npm run test` — all pass
4. No orphaned TODO/FIXME without a tracking issue
5. New modules have corresponding test files
## Self-Evolution Protocol
You are an evolving system. During every session:
1. **Observe.** When you discover a non-obvious pattern, constraint, or convention in the codebase that isn't documented, log it to `.claude/memory/observations.jsonl`. Verify it with a grep before logging — never log a guess.
2. **Learn from corrections.** When the user corrects you, log the correction to `.claude/memory/corrections.jsonl`. This is your most valuable signal.
3. **Consult memory.** At the start of complex tasks, read `.claude/memory/learned-rules.md` for patterns accumulated from past sessions.
4. **Never make the same mistake twice.** If a correction matches a previous one, and it hasn't been promoted to learned-rules.md yet, promote it immediately.
Read `.claude/memory/README.md` for the full memory protocol.
## Things You Must Never Do
- Commit to main directly
- Read or modify .env or secret files
- Run destructive commands without confirmation
- Install dependencies without justification
- Leave dead code in the codebase
- Write tests that only test mocks rather than behavior
- Swallow errors silently
- Skip input validation
- Modify `.claude/memory/learned-rules.md` without running /project:evolve
What to customize: The Commands section (swap in your actual build/test/lint commands), the Architecture section (your real folder structure), and the Conventions section (adjust to your stack). Everything else applies universally.
Step 3: Settings — Permissions and Safety
Create .claude/settings.json:
{
"$schema": "https://json.schemastore.org/claude-code-settings.json",
"permissions": {
"allow": [
"Bash(npm run *)",
"Bash(npx *)",
"Bash(node *)",
"Bash(git status)",
"Bash(git diff *)",
"Bash(git log *)",
"Bash(git branch *)",
"Bash(git show *)",
"Bash(git stash *)",
"Bash(gh issue *)",
"Bash(gh pr *)",
"Bash(cat *)",
"Bash(ls *)",
"Bash(find *)",
"Bash(head *)",
"Bash(tail *)",
"Bash(wc *)",
"Bash(grep *)",
"Read",
"Write",
"Edit",
"Glob",
"Grep"
],
"deny": [
"Bash(rm -rf *)",
"Bash(rm -r *)",
"Bash(sudo *)",
"Bash(eval *)",
"Bash(git push --force *)",
"Bash(git reset --hard *)",
"Bash(npm publish *)",
"Read(./.env)",
"Read(./.env.*)",
"Read(./**/*.pem)",
"Read(./**/*.key)"
]
}
}
How this works: Commands in the allow list run without prompting. Commands in the deny list are blocked entirely. Anything not in either list triggers a confirmation prompt. This middle ground is intentional — you want Claude to run your test suite freely, never touch your secrets, and ask before doing anything unexpected.
What to customize: If you use pnpm, bun, or make, add those patterns to the allow list. Add project-specific directories to the deny list if they should be off-limits.
Step 4: Rules — Path-Scoped Intelligence
Rules are instruction files that load only when Claude is working with matching file paths. The front matter paths: field controls this. Claude never reads your security rules while editing a CSS file — keeping context lean and relevant.
Security Rules
Create .claude/rules/security.md:
---
description: Security rules for API handlers, auth, services, and middleware
paths:
- "src/api/**/*"
- "src/services/**/*"
- "src/middleware/**/*"
- "src/auth/**/*"
---
# Security Rules
## Input Handling
Validate shape AND content. Zod validates structure. You still need to check:
- String lengths (prevent memory exhaustion)
- Numeric ranges (prevent overflow)
- URL/email format (prevent SSRF and injection)
- File type AND content, not just extension
Never trust Content-Type headers. Validate the actual payload.
## Authorization
Auth checks happen in middleware, never scattered through handlers. Every route denies by default.
For any endpoint that accepts a resource ID (user ID, document ID, order ID): verify the authenticated user has permission to access THAT specific resource — not just that they're logged in. IDOR (Insecure Direct Object Reference) is among the most common web vulnerabilities.
Token validation: check expiry, issuer, audience, AND signature. Not just presence.
## Database
Parameterized queries only. If you see string concatenation near a query, stop and fix it.
When building dynamic queries (filters, sorts, search): whitelist allowed field names explicitly. Never pass user input as a column name or sort direction.
## Secrets and Data
If you encounter a hardcoded secret during a session, flag it immediately and recommend rotation.
PII in logs: mask to the last 4 characters or hash it. This includes email addresses, phone numbers, and IP addresses.
API responses: return only the fields the client needs. Never expose internal IDs, timestamps, or metadata that reveals system internals.
Error responses to clients: return the error code and a safe message. Never expose stack traces, SQL errors, file paths, or internal service names.
## Dependencies
Before adding any new package:
1. Check last publish date (stale > 2 years is a red flag)
2. Check open security advisories on GitHub
3. Check weekly downloads (very low = potential typosquatting)
4. Verify the license is compatible
5. Run `npm audit` after installation
API Design Rules
Create .claude/rules/api-design.md:
---
description: API design patterns for HTTP handlers and route definitions
paths:
- "src/api/**/*"
- "src/routes/**/*"
- "src/handlers/**/*"
---
# API Design Rules
## Handler Structure
Every handler follows this exact pattern:
async function handleSomething(req, res) {
// 1. Validate input
const parsed = schema.safeParse(req.body);
if (!parsed.success) {
return res.status(400).json({ data: null, error: formatZodError(parsed.error) });
}
// 2. Call business logic (from core/, never inline)
const result = await doTheThing(parsed.data);
// 3. Handle result
if (result.error) {
return res.status(result.error.status).json({ data: null, error: result.error });
}
return res.status(200).json({ data: result.data, error: null });
}
No business logic in handlers. Handlers are adapters between HTTP and core/. If your handler exceeds 20 lines, logic is in the wrong place.
## Response Shape
Every response, always, no exceptions:
{ data: T | null, error: { code: string, message: string } | null }
Never return bare objects. Never return different shapes for success vs error.
## Pagination
All list endpoints paginate. Default limit: 20. Max: 100. Always include:
{ data: T[], meta: { total, limit, offset, hasMore }, error: null }
## Error Codes
Use specific error codes, not just HTTP status numbers:
NOT_FOUND, VALIDATION_ERROR, UNAUTHORIZED, FORBIDDEN, RATE_LIMITED, CONFLICT, INTERNAL_ERROR
HTTP status codes are for transport. Error codes are for the application.
## Rate Limiting
Every endpoint has a rate limit. Defaults:
- Authenticated: 100 requests/minute
- Unauthenticated: 20 requests/minute
- Auth endpoints (login, register, reset): 5 requests/minute per IP
Return a `Retry-After` header when rate limiting triggers.
Performance Rules
Create .claude/rules/performance.md:
---
description: Performance patterns that prevent common production issues
paths:
- "src/**/*"
---
# Performance Rules
## The Three Things That Cause 90% of Production Performance Problems
### 1. N+1 Queries
If you're querying inside a loop, you have an N+1. Batch it.
// WRONG — hits the database once per user
for (const id of userIds) {
const user = await db.user.findUnique({ where: { id } });
}
// RIGHT — single query
const users = await db.user.findMany({ where: { id: { in: userIds } } });
Before writing any database code, ask: "Am I calling this inside a loop or a .map()?" If yes, batch it.
### 2. Missing Indexes
Every new query pattern needs an index check. If you're filtering by `email`, there must be an index on `email`. If you're filtering by `status` AND `createdAt`, there must be a compound index.
When writing a new query: immediately check whether the queried fields are indexed. If not, include the migration in the same PR.
### 3. Unbounded Queries
Never SELECT * without a LIMIT. Never fetch an entire collection to filter it in application code.
// WRONG
const allOrders = await db.order.findMany();
const pending = allOrders.filter(o => o.status === 'pending');
// RIGHT
const pending = await db.order.findMany({
where: { status: 'pending' },
take: 100
});
## Async Patterns
Set timeouts on every external call. Defaults: 10s for APIs, 30s for databases, 5s for cache.
Use `Promise.all()` for independent concurrent operations. Use `Promise.allSettled()` when operations should fail independently.
Never block the event loop with synchronous work in hot paths. If a computation takes > 50ms, offload it.
## Caching
Cache at the service boundary, never inside core logic. Cache keys must be namespaced and versioned: `v1:users:{id}`. Always set a TTL. An infinite cache is a bug.
Core Invariants (loads everywhere)
Create .claude/rules/core-invariants.md:
---
description: Critical rules that load on every file edit, compression-proof
paths:
- "**/*"
---
# Core Invariants
These rules load on every file touch. They exist because violating them caused production bugs.
Replace these placeholders with your own hard-won lessons:
1. **[Your most painful bug].** Describe the exact pattern that must never happen, and the correct alternative.
2. **[Your second most painful bug].** Same format.
3. **[Critical safety rule].** Something that causes data loss, security holes, or silent failures when violated.
The `paths: ["**/*"]` setting means this file reloads on every file operation. Even when the conversation context gets long and compressed, these rules get re-injected fresh on every tool call. They are compression-proof.
Start with one or two placeholders and let the evolution system fill this over time. Rules that keep recurring in violations.jsonl are your candidates.
Step 5: Agents — Specialized Subagents
Agents are subagent definitions with their own system prompts and tool access. When Claude spawns one, it runs in a separate context window focused on a single job.
Architect Agent
Create .claude/agents/architect.md:
---
name: architect
description: >
Task planner for complex changes. Use PROACTIVELY when a task touches 3+ files,
involves a new feature (not a bug fix), or requires understanding how components
interact. Invoke BEFORE writing code. Skip for simple single-file changes.
model: claude-sonnet-4-5
tools: Read, Grep, Glob, Bash
---
You are a systems architect. You PLAN. You never write implementation code.
## Process
1. Restate the goal in one sentence. If you can't, the request is unclear — ask.
2. Grep the codebase for existing patterns related to this task. List what you found.
3. Map every file that needs to change or be created. One sentence per file on what changes.
4. Identify what could break. Check: what imports the files you're changing? What tests cover them?
5. Produce this exact output:
PLAN: [one-line summary]
CHANGE:
- [path] - [what changes]
CREATE:
- [path] - [purpose]
- [path.test.ts] - [what it tests]
RISK:
- [risk]: [mitigation]
ORDER:
1. [first step]
2. [second step]
VERIFY:
- [how to confirm each step works]
## Rules
- If the task needs fewer than 3 file changes, say "This doesn't need a plan. Just do it." and stop.
- Never suggest patterns you haven't verified exist in the codebase.
- Flag when a task should be split into multiple PRs.
- Estimate blast radius: how many existing tests might break.
Reviewer Agent
Create .claude/agents/reviewer.md:
---
name: reviewer
description: >
Code reviewer. Use before any git commit, when validating an implementation,
or when asked to review a diff. Focuses on bugs and security, not style.
model: claude-sonnet-4-5
tools: Read, Grep, Glob
---
You are a code reviewer who catches bugs that cause production incidents.
## What You Check (in priority order)
1. **Will this crash?** Null access, undefined properties, unhandled promise rejections, off-by-one errors, division by zero, type coercion surprises.
2. **Is this exploitable?** Unvalidated input reaching a query, missing auth check, IDOR, leaked error details, hardcoded secrets.
3. **Will this be slow?** N+1 queries, missing indexes, unbounded fetches, synchronous blocking in async context.
4. **Is this tested?** Are critical paths covered? Do the tests assert behavior, not just implementation? Could the test pass with a broken implementation?
5. **Will the next person understand this?** Only flag readability issues if they would cause a real misunderstanding — not style preferences.
## Output Format
VERDICT: SHIP IT | NEEDS WORK | BLOCKED
CRITICAL (must fix before merge):
- [file:line] [issue] -> [specific fix]
IMPORTANT (should fix):
- [file:line] [issue] -> [suggestion]
GAPS:
- [untested scenario that should have a test]
GOOD:
- [specific things done well]
## Rules
- Critical means: will cause a bug, security hole, or data loss. Nothing else qualifies as critical.
- Every finding includes a specific fix. "This could be better" is not a finding.
- If the code is good, say SHIP IT and explain what's done well. Don't invent problems.
- Check that new code follows patterns already in the codebase.
Step 6: Commands — Slash Command Workflows
Claude Code exposes any .md file in .claude/commands/ as a slash command: commands/review.md → /project:review. The ! prefix in command files executes shell commands at invocation time, injecting their output into the prompt automatically.
Pre-Commit Review
Create .claude/commands/review.md:
---
description: Pre-commit review pipeline. Runs type checks, lint, tests, then reviews the diff.
---
## Pre-flight
!`git diff --name-only main...HEAD 2>/dev/null || git diff --name-only HEAD~1 2>/dev/null || echo "No diff available"`
!`npm run typecheck 2>&1 | tail -15`
!`npm run lint 2>&1 | tail -15`
!`npm run test -- --changedSince=main 2>&1 | tail -25`
## Diff
!`git diff main...HEAD 2>/dev/null || git diff HEAD~1 2>/dev/null || git diff --cached`
## Instructions
1. If any pre-flight check failed, list failures first with exact fixes.
2. Review the diff for: bugs (logic errors, null risks, race conditions), security gaps (unvalidated input, missing auth, data exposure), performance issues (N+1 queries, missing indexes, blocking calls), and test gaps (untested critical paths).
3. For each issue: file, line, what's wrong, how to fix it. Be specific.
4. Verdict: SHIP IT / NEEDS WORK / BLOCKED.
5. If SHIP IT: suggest a commit message in conventional commits format.
Usage: Type /project:review before committing.
Fix a GitHub Issue
Create .claude/commands/fix-issue.md:
---
description: End-to-end bug fix from a GitHub issue number.
argument-hint: [issue-number]
---
!`gh issue view $ARGUMENTS 2>/dev/null || echo "Could not fetch issue #$ARGUMENTS. Describe the bug manually."`
## Workflow
1. **Root cause.** Read the issue. Grep the codebase. Trace the code path. State the root cause in one sentence before writing any fix.
2. **Fix.** Minimal change. Don't refactor. Don't "improve" adjacent code. Solve the bug.
3. **Test.** Write a test that fails without your fix and passes with it. This test should have caught the original bug.
4. **Verify.** Run `npm run typecheck && npm run lint && npm run test`. All must pass.
5. **Commit.** `fix(scope): description (fixes #$ARGUMENTS)`
6. **Report.** One paragraph: root cause, what you changed, what test you added.
Usage: Type /project:fix-issue 42 (replacing 42 with a real issue number).
Session Boot
Create .claude/commands/boot.md:
---
description: Session primer. Loads memory and runs the verification sweep on all learned rules.
---
## Load Memory
### Learned Rules
!`cat .claude/memory/learned-rules.md 2>/dev/null || echo "No learned rules yet"`
### Last Session Score
!`tail -1 .claude/memory/sessions.jsonl 2>/dev/null || echo "No session history"`
### Unresolved Violations
!`tail -5 .claude/memory/violations.jsonl 2>/dev/null || echo "No violations logged"`
## Instructions
1. Read every rule in learned-rules.md. For each rule that has a `verify:` line, run that check now.
2. Report results:
- All pass → "All rules verified. Ready to work."
- Any fail → list each violation with file:line and the specific fix required.
3. If sessions.jsonl has 5+ entries, report a one-line trend summary (corrections increasing or decreasing, most common violations).
4. You are now primed. Proceed with the user's task.
Usage: Type /project:boot at the start of a session to force the full verification sweep with loaded context.
Evolution Audit
Create .claude/commands/evolve.md:
---
description: Reviews the learning system and proposes rule promotions, graduations, and pruning. Run weekly or when learned-rules.md gets full.
---
## Current State
### Learned Rules
!`cat .claude/memory/learned-rules.md 2>/dev/null || echo "No learned rules yet"`
### Recent Corrections (last 20)
!`tail -20 .claude/memory/corrections.jsonl 2>/dev/null || echo "No corrections logged"`
### Recent Observations (last 20)
!`tail -20 .claude/memory/observations.jsonl 2>/dev/null || echo "No observations logged"`
### Previous Evolution Decisions
!`tail -40 .claude/memory/evolution-log.md 2>/dev/null || echo "No evolution history"`
## Your Task
You are the meta-engineer. Your job is to improve the system that runs you.
### Step 1: Analyze Corrections
Group corrections by pattern. Look for:
- The same correction appearing 2+ times (should already be in learned-rules — if not, promote it now)
- Correction clusters pointing to a gap in CLAUDE.md or a rules/ file
- Corrections that contradict existing rules (the rule is wrong, not the user)
### Step 2: Analyze Observations
Group observations by type. Look for:
- High-confidence observations confirmed multiple times
- Observations that match corrections (convergent signals are the strongest evidence)
- Architecture or gotcha observations that could prevent future bugs
### Step 3: Audit Learned Rules
For each rule in learned-rules.md, evaluate:
- **Still relevant?** Does the codebase still use this pattern?
- **Promotion candidate?** If it's been followed for 10+ sessions without exception, propose moving it to CLAUDE.md or a rules/ file.
- **Redundant?** Is it now covered by a linter rule, a rules/ file, or CLAUDE.md directly?
- **Too vague?** Could Claude follow it without interpretation? If not, rewrite it.
### Step 4: Check Evolution Log
Read evolution-log.md. Never re-propose a previously rejected rule unless the user explicitly asks.
### Step 5: Propose Changes
For each proposal:
PROPOSE: [action]
Rule: [the rule text]
Source: [corrections / observations / learned-rules]
Evidence: [why this should change]
Destination: [learned-rules.md | CLAUDE.md | rules/X.md | DELETE]
Action types:
- PROMOTE: Move from observations to learned-rules
- GRADUATE: Move from learned-rules to CLAUDE.md or a rules/ file
- PRUNE: Remove redundant or outdated learned rule
- UPDATE: Modify existing rule based on new evidence
- ADD: New rule derived from correction patterns
### Step 6: Wait for Approval
List all proposals. Do NOT apply any changes yet.
For each proposal the user will say: approve, reject, or modify.
Apply only approved changes. Log all decisions — including rejections — to evolution-log.md.
### Constraints
- Never remove security rules
- Never weaken completion criteria
- Never add rules that contradict CLAUDE.md
- learned-rules.md max 50 lines — force graduation or pruning if at capacity
- Every rule must be specific enough to test compliance
- Prefer specificity over abstraction
Usage: Type /project:evolve weekly, or whenever Claude seems to be repeating the same mistakes.
Sync Commands (Toolchain Auto-Detection)
The Commands section of CLAUDE.md is the one part of this system that cannot self-update. It’s static config — Claude has no way to infer your build tools unless you tell it. If you paste in the template and forget to update it, Claude will try to run npm run test on a Python project and fail silently on the wrong commands.
The solution is a one-shot command that reads your project files and writes the correct values into CLAUDE.md for you. Run it once on setup, and again any time you change your toolchain.
Create .claude/commands/sync-commands.md:
---
description: Detects the project's toolchain and updates the Commands section in CLAUDE.md.
---
## Project Signals
!`cat package.json 2>/dev/null | head -40 || echo "No package.json"`
!`cat Makefile 2>/dev/null | grep -E "^[a-z].*:" | head -20 || echo "No Makefile"`
!`cat pyproject.toml 2>/dev/null || cat setup.cfg 2>/dev/null | head -30 || echo "No Python config"`
!`cat Cargo.toml 2>/dev/null | head -20 || echo "No Cargo.toml"`
!`cat go.mod 2>/dev/null | head -5 || echo "No go.mod"`
!`ls .github/workflows/*.yml 2>/dev/null | head -5 || echo "No CI workflows"`
!`cat $(ls .github/workflows/*.yml 2>/dev/null | head -1) 2>/dev/null | grep -E "run:|npm |yarn |pnpm |python |pytest |cargo |go " | head -20 || echo "No CI commands found"`
## Instructions
1. Read the project signals above. Identify the package manager, test runner, linter, type checker, and build tool in use.
2. Check the CI workflow file for the exact commands used in the pipeline — these are the ground truth for what "passing" means on this project.
3. Derive the correct command for each of these roles:
- **dev**: local development server (if applicable)
- **test**: run the test suite
- **lint**: run the linter
- **build**: compile or bundle for production
- **typecheck**: static type checking (if applicable)
4. Produce a replacement Commands section in this exact format — commands only, no extra commentary:
## Commands
[dev command] # Start dev server
[test command] # Run tests
[lint command] # Lint check
[build command] # Production build
[typecheck command] # Type checking (omit if not applicable)
5. Then open CLAUDE.md and replace the existing Commands section with the one you just produced.
6. Confirm: "Commands updated. Now using: [list each command on one line]."
## Common Toolchain Patterns
Node/npm: npm run dev / npm test / npm run lint / npm run build
Node/pnpm: pnpm dev / pnpm test / pnpm lint / pnpm build
Node/yarn: yarn dev / yarn test / yarn lint / yarn build
Node/bun: bun dev / bun test / bun lint / bun build
Python: python -m pytest / ruff check . / mypy src/ (no dev/build in most cases)
Go: go run ./... / go test ./... / go vet ./... / go build ./...
Rust: cargo run / cargo test / cargo clippy / cargo build
Make-based: make dev / make test / make lint / make build (verify targets exist first)
If a role has no equivalent command (e.g. a CLI tool with no dev server), omit that line from the Commands section entirely.
Usage: Type /project:sync-commands once when setting up a new project, and again any time you change your build toolchain (e.g. switching from Jest to Vitest, adding a new lint step, migrating to a different package manager). It reads your package.json, Makefile, pyproject.toml, Cargo.toml, and CI workflow files to determine the correct commands, then patches CLAUDE.md directly.
Note: The Completion Criteria section of
CLAUDE.mdreferences these commands by name (e.g.npm run typecheck). After running/project:sync-commands, verify that the Completion Criteria section still matches the updated commands.
Step 7: The Evolution Engine
This is the core of the system. Create .claude/memory/README.md — Claude reads this to understand how to use the memory infrastructure.
But the engine that drives learning is a set of behaviors you define directly in CLAUDE.md (the Self-Evolution Protocol section above) combined with the explicit format of the memory files below. There’s no separate “auto-triggered skill” — Claude follows the evolution protocol because CLAUDE.md instructs it to.
What makes this different from a static CLAUDE.md is the verification check attached to every rule:
- Never use the spread pattern to merge options in fetchJSON.
verify: Grep("\.\.\.options", path="src/api/client.js") → 0 matches
[source: corrected 2x, 2026-03-28]
The verify: line isn’t runnable code — it’s an instruction Claude executes as a grep check during the verification sweep at session start. Claude reads the pattern, runs the search, and confirms the result matches the expectation. Rules without a verify: line are debt: they rely on Claude remembering. Rules with one are enforced mechanically.
The principle: A rule without a verification check is a wish. A rule with one is a guardrail.
Step 8: Memory Files
Memory System README
Create .claude/memory/README.md:
# Memory System
This directory is Claude's learning infrastructure. It persists observations, corrections, and graduated rules across sessions.
## How It Works
Session start
→ /project:boot loads memory and runs verification sweep
→ Every rule with a verify: line gets grep-checked
→ Violations surface before work begins
During session
→ observations.jsonl — verified codebase discoveries (never guesses)
→ corrections.jsonl — user corrections with auto-generated verify checks
→ violations.jsonl — rule violations caught by verification sweep
End of session
→ sessions.jsonl — session scorecard with trend data
Periodic review
→ /project:evolve — promotes, prunes, and graduates accumulated signals
## File Purposes
### observations.jsonl
Append-only log. One JSON object per line. Claude writes here when it discovers something non-obvious, after verifying it with grep.
{"timestamp": "2026-03-28T14:30:00Z", "type": "convention", "hypothesis": "All service functions return Promise<Result<T>>", "evidence": "Grep found 23 occurrences, 0 counter-examples", "confidence": "confirmed", "file_context": "src/services/", "verify": "Grep for non-Result returns in services/ → 0 matches"}
Types: convention, gotcha, dependency, architecture, performance, pattern
Confidence: low (inferred), medium (observed once), high (observed multiple times), confirmed (zero counter-examples found)
### corrections.jsonl
Append-only log. Claude writes here when the user corrects its behavior.
{"timestamp": "2026-03-28T16:00:00Z", "correction": "Don't use ternary operators in this project", "context": "Was writing a ternary in a handler", "category": "style", "times_corrected": 1, "verify": "Grep('? .* :', path='src/') → 0 matches"}
The times_corrected field tracks repeat corrections. When the same pattern reaches 2, Claude auto-promotes it to learned-rules.md without waiting for /project:evolve.
Categories: style, architecture, security, testing, naming, process, behavior
### violations.jsonl
Append-only log. Records every rule violation caught by the verification sweep.
Used by /project:evolve to identify rules that need escalation — recurring violations mean the rule should graduate to CLAUDE.md or become a linter rule.
### sessions.jsonl
One scorecard per session. Tracks corrections received, rules checked and passed, observations made and verified.
Used for trend detection: are corrections decreasing over time? If not, the rules aren't working or aren't being consulted.
### learned-rules.md
Curated rules that graduated from corrections and observations. Claude reads this at the start of complex tasks. Every rule here was promoted because it was corrected 2+ times or explicitly approved via /project:evolve.
Max 50 lines — enforced to force graduation or pruning, keeping the file lean and high-signal.
### evolution-log.md
Audit trail of every /project:evolve run. Records what was proposed, approved, rejected, and why. Prevents the system from re-proposing rejected rules.
## Promotion Ladder
| Signal | Destination |
|-------------------------------------------|--------------------------------------|
| Corrected once | corrections.jsonl (logged) |
| Corrected twice, same pattern | learned-rules.md (auto-promoted) |
| Observation confirmed, 0 counter-examples | learned-rules.md (auto-promoted) |
| In learned-rules 10+ sessions, always followed | Candidate for CLAUDE.md or rules/ |
| Rejected during /project:evolve | evolution-log.md (never re-proposed) |
## Rules for Writing to Memory
1. Observations are cheap — log them. Low-confidence observations are fine as long as they're labeled.
2. Corrections are gold — every correction gets logged, no exceptions.
3. Learned rules are expensive — they load into context every session. Each must be actionable, testable, and non-redundant.
4. Never delete correction logs — they're provenance.
5. learned-rules.md caps at 50 lines — forces graduation or pruning.
Learned Rules (starts empty)
Create .claude/memory/learned-rules.md:
# Learned Rules
Rules that graduated from observations and corrections. Loaded at the start of complex tasks.
Max 50 lines. Rules approaching that limit should be promoted to CLAUDE.md or rules/ files.
Each rule includes a source annotation AND a machine-checkable verify line.
---
<!-- Example format:
- Never use the spread pattern to merge options in fetchJSON.
verify: Grep("\.\.\.options", path="src/api/client.js") → 0 matches
[source: corrected 2x, 2026-03-28]
- All service functions must return Result<T>.
verify: Grep("export.*function.*Promise<(?!Result)", path="src/services/") → 0 matches
[source: verified observation, 2026-04-01]
-->
Evolution Log (starts empty)
Create .claude/memory/evolution-log.md:
# Evolution Log
Audit trail of /project:evolve runs. Records all proposals, approvals, and rejections.
Rejected rules are never re-proposed unless the user explicitly asks.
Step 9: Automation with Hooks (Optional but Recommended)
The base system works, but it relies on Claude remembering to run the verification sweep and log corrections. Hooks make these behaviors structural — they fire automatically, not optionally.
Update .claude/settings.json with hooks added to the permissions you already have:
{
"$schema": "https://json.schemastore.org/claude-code-settings.json",
"permissions": {
"allow": [
"Bash(npm run *)",
"Bash(npx *)",
"Bash(node *)",
"Bash(git status)",
"Bash(git diff *)",
"Bash(git log *)",
"Bash(git branch *)",
"Bash(git show *)",
"Bash(git stash *)",
"Bash(gh issue *)",
"Bash(gh pr *)",
"Bash(cat *)",
"Bash(ls *)",
"Bash(find *)",
"Bash(head *)",
"Bash(tail *)",
"Bash(wc *)",
"Bash(grep *)",
"Read",
"Write",
"Edit",
"Glob",
"Grep"
],
"deny": [
"Bash(rm -rf *)",
"Bash(rm -r *)",
"Bash(sudo *)",
"Bash(eval *)",
"Bash(git push --force *)",
"Bash(git reset --hard *)",
"Bash(npm publish *)",
"Read(./.env)",
"Read(./.env.*)",
"Read(./**/*.pem)",
"Read(./**/*.key)"
]
},
"hooks": {
"SessionStart": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "echo \"[EVOLUTION BOOT] Session started. Learned rules: $(wc -l < .claude/memory/learned-rules.md 2>/dev/null || echo 0) lines. Corrections logged: $(wc -l < .claude/memory/corrections.jsonl 2>/dev/null || echo 0). READ .claude/memory/learned-rules.md BEFORE STARTING WORK. RUN VERIFICATION SWEEP ON ALL RULES WITH verify: LINES.\"",
"timeout": 5,
"statusMessage": "Booting evolution engine..."
}
]
}
],
"PreToolUse": [
{
"matcher": "Edit|Write",
"hooks": [
{
"type": "command",
"command": "echo \"[EVOLUTION] Before editing: check if this file has path-scoped rules in .claude/rules/. Check learned-rules.md for relevant patterns.\"",
"timeout": 3
}
]
}
],
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "echo \"[EVOLUTION] Session ending. If corrections were received or observations made, ensure they are logged to .claude/memory/. Write session scorecard to sessions.jsonl.\"",
"timeout": 3
}
]
}
]
}
}
What each hook does:
| Hook | When | What it does |
|---|---|---|
SessionStart | Every new session | Injects a message telling Claude to read learned-rules.md and run the verification sweep before seeing your first message |
PreToolUse on Edit/Write | Before every file edit | Reminds Claude to check path-scoped rules and learned-rules for the file it’s about to touch |
Stop | Session ending | Tells Claude to log corrections, observations, and write the session scorecard |
The difference between “the instructions say to do it” and “the system makes it structurally difficult to skip.”
How the Evolution Loop Works in Practice
Here’s what the system looks like across sessions:
Session 1. You correct Claude: “we never use ternary operators here, always use if/else.” Claude logs the correction to corrections.jsonl and generates a verify pattern: Grep("? .* :", path="src/") → 0 matches. It applies the fix immediately.
Session 3. Claude writes a ternary again in a different file. You correct it again. Claude sees times_corrected: 2 for this pattern and auto-promotes it to learned-rules.md:
- Never use ternary operators. Always use if/else blocks.
verify: Grep("[?] .* : ", path="src/") → 0 matches
[source: corrected 2x, 2026-03-30]
Claude tells you it’s learned this permanently and will auto-verify from now on.
Session 5. Claude starts a complex task. Before writing anything, the verification sweep runs. It executes every verify: check in learned-rules.md. The ternary grep returns 0 matches. All clear. Claude proceeds, writing if/else blocks because the rule is loaded. Correction plus verification equals double enforcement.
Session 8. During normal work, Claude notices every service function wraps its return in a Result<T> type. Instead of logging a guess, it immediately greps for counter-examples. It finds 0 across 15 functions. Confidence: confirmed. It auto-promotes with a verify check: “Verified and added as rule: All service functions return Result
Session 12. You run /project:evolve. It reads sessions.jsonl: corrections dropped from 3 per session to 0.5 over the last 10 sessions. Two rules have passed verification for 10+ consecutive sessions. It proposes graduating those to CLAUDE.md. You approve, reject, or modify each proposal. Nothing changes without your sign-off.
Session 20. The system has 8 learned rules with verification checks, 3 rules graduated to permanent config, 2 pruned. The verification sweep at session start catches violations before you even describe your task.
.gitignore Recommendations
Add these to your .gitignore. The raw session logs are personal — the curated knowledge files are worth committing:
# Claude Code local overrides
CLAUDE.local.md
.claude/settings.local.json
# Raw evolution logs — personal session data
.claude/memory/observations.jsonl
.claude/memory/corrections.jsonl
.claude/memory/violations.jsonl
.claude/memory/sessions.jsonl
# Commit these — they're curated team knowledge
# .claude/memory/learned-rules.md
# .claude/memory/evolution-log.md
Testing Your Setup
After creating all the files, launch Claude Code and verify each layer:
Cognitive core: Ask “What are your completion criteria?” Claude should list the 5 checks from CLAUDE.md without hesitation.
Decision framework: Ask Claude to add a utility function. It should grep for existing patterns before writing a line of code.
Path-scoped rules: Ask Claude to create an API endpoint. The security and API design rules should activate — you’ll see it mention input validation, response shapes, and auth checks.
Review command: Type
/project:review. It should run your test suite, linter, and type checker, then review the diff with a verdict.Evolution — correction capture: Correct Claude on something (“we don’t do it that way, we always X”). It should acknowledge and log the correction. Correct it again on the same pattern. It should auto-promote to
learned-rules.md.Evolution — audit: After a few sessions with corrections and observations, run
/project:evolve. It should analyze the logs and propose concrete changes for your approval.Verification sweep: Add a learned rule with a
verify:line that you know will fail (grep for a pattern you know exists in your code). Start a new session and run/project:boot. Claude should detect the violation and surface it before you ask for anything. Fix the violation, start another session — the sweep should pass silently.Session scoring: After a session where Claude made and logged corrections, check
.claude/memory/sessions.jsonl. It should contain an entry with correction count, rules checked, and pass/fail rates.
Frequently Asked Questions
Does this affect all my Claude projects?
No. The .claude/ folder and CLAUDE.md are project-scoped. They only affect Claude Code sessions running in that specific directory. Other projects are completely unaffected.
What if I want certain rules across all projects?
Create ~/.claude/CLAUDE.md in your home directory. It loads into every Claude Code session regardless of project. Good for personal preferences like “always use conventional commits” or “I prefer early returns.”
How big should CLAUDE.md be?
Under 150 lines. Beyond that, instruction adherence degrades as the context grows noisy. Move domain-specific rules to .claude/rules/ files instead of growing CLAUDE.md.
Won’t the memory files grow forever?
The .jsonl files are append-only and grow slowly — maybe 5–10 entries per session. Running /project:evolve processes them by promoting confirmed patterns to learned-rules. You can archive old entries after they’ve been processed. learned-rules.md is capped at 50 lines by design, which forces regular graduation or pruning.
Can I version control the memory files?
Recommended approach: gitignore the raw .jsonl logs (personal session data) and commit learned-rules.md and evolution-log.md (curated team knowledge). See the .gitignore section above.
What if Claude doesn’t follow the rules? Three causes, in order of likelihood:
CLAUDE.mdis too long — shorten it below 150 lines and move domain-specific rules to.claude/rules/files.- The rule is too vague — “write good code” is useless; “functions max 30 lines, max 3 nesting levels” is actionable.
- The rule has no
verify:line — rules with machine-checkable tests get enforced during the sweep; rules without them rely on Claude remembering. Add a verify line to every rule.
Can I use this with Python, Go, Rust, or other stacks?
Yes. The system is stack-agnostic. Swap the npm commands for your equivalents (pytest, go test, cargo test), adjust the folder structure, and update conventions. The decision framework, evolution loop, agents, and memory system work identically regardless of language.
How is this different from just writing a good CLAUDE.md?
A static CLAUDE.md tells Claude what to do. This system adds three things a static file can’t: verification checks that enforce rules mechanically via grep, a promotion ladder that moves knowledge through confidence tiers based on evidence, and session scoring that tells you whether the system is actually improving over time. A good CLAUDE.md sets the starting point. This system raises the floor every session.
Quick Start Script
Save this as setup-claude.sh and run it from your project root to create the folder structure in one shot:
#!/bin/bash
echo "Creating .claude/ folder structure..."
mkdir -p .claude/rules
mkdir -p .claude/agents
mkdir -p .claude/commands
mkdir -p .claude/memory
echo ""
echo "Structure created. Now create these files:"
echo ""
echo " CLAUDE.md (Step 2)"
echo " .claude/settings.json (Step 3)"
echo " .claude/rules/security.md (Step 4)"
echo " .claude/rules/api-design.md (Step 4)"
echo " .claude/rules/performance.md (Step 4)"
echo " .claude/rules/core-invariants.md (Step 4)"
echo " .claude/agents/architect.md (Step 5)"
echo " .claude/agents/reviewer.md (Step 5)"
echo " .claude/commands/review.md (Step 6)"
echo " .claude/commands/fix-issue.md (Step 6)"
echo " .claude/commands/boot.md (Step 6)"
echo " .claude/commands/evolve.md (Step 6)"
echo " .claude/commands/sync-commands.md (Step 6)"
echo " .claude/memory/README.md (Step 8)"
echo " .claude/memory/learned-rules.md (Step 8)"
echo " .claude/memory/evolution-log.md (Step 8)"
echo ""
echo "Then customize CLAUDE.md with your actual commands and folder structure."
echo "Or run /project:sync-commands on first launch to auto-detect your toolchain."
echo ""
echo "Slash commands are invoked as /project:<filename> — e.g. /project:review"
echo ""
echo "Add to .gitignore:"
echo " CLAUDE.local.md"
echo " .claude/settings.local.json"
echo " .claude/memory/observations.jsonl"
echo " .claude/memory/corrections.jsonl"
echo " .claude/memory/violations.jsonl"
echo " .claude/memory/sessions.jsonl"
echo ""
echo "Done. Run 'claude' in this directory to start."
The gap between session 1 and session 20 is where the real value accumulates. Session 1 will feel similar to a well-written CLAUDE.md. By session 20, the rules are specific to your codebase, every one is backed by a machine-checkable test, and corrections have been trending toward zero for weeks.